书接上文:爬取厦门58同城二手房数据进行数据分析(一) 这一篇主要对上一篇文章爬取下来的数据进行一些探索性分析和可视化,并且建立一个简单的预测模型进行房价预测。
数据分析及可视化
数据预处理
首先导包,由于seaborn画图不支持中文显示,因此还需要加几行代码: 1
2
3
4
5
6
7import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题1
2
3
4
5data = pd.read_csv('data.csv')
data = data.drop(columns=['Unnamed: 0', 'title', 'url', '产权年限', 'location2'])
data = data[data['location1'] != '厦门周边'] # 删除厦门周边的数据
data = data.dropna()
data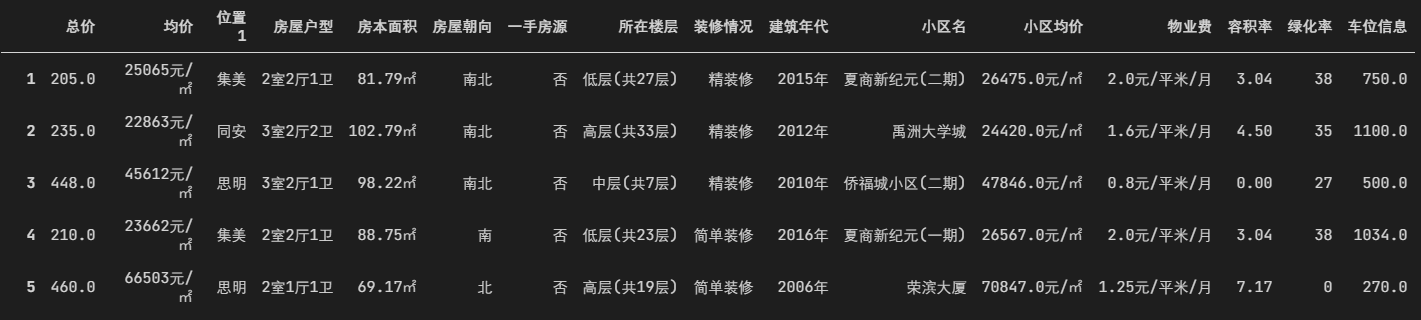
为了方便后续的工作,我们在将数据做一些简单的处理: 1
2
3
4
5
6
7
8
9
10
11
12
13
14data['室'] = data['房屋户型'].apply(lambda x: int(x[0]))
data['厅'] = data['房屋户型'].apply(lambda x: int(x[2]))
data['卫'] = data['房屋户型'].apply(lambda x: int(x[4]))
data['均价'] = data['均价'].apply(lambda x: float(x.split('元')[0]))
data['房本面积'] = data['房本面积'].apply(lambda x: float(x[:-1]))
data['建筑年代'] = data['建筑年代'].apply(lambda x: int(x[:-1]))
data['总楼层'] = data['所在楼层'].apply(lambda x: int(x[4:-2]))
data['所在楼层'] = data['所在楼层'].apply(lambda x: x[0])
data['小区均价'] = data['小区均价'].apply(
lambda x: float(x.split('元')[0]))
data['物业费'] = data['物业费'].apply(
lambda x: float(x.split('元')[0]))
data['绿化率'] = data['绿化率'].apply(float)
data['车位信息'] = data['车位信息'].apply(int)
单变量可视化
价格分布
厦门市的房价总体来说还是非常贵的,一平方米平均要四万多,一套下来得四百多万,买不起买不起 1
2
3
4sns.distplot(data['均价'])
data['均价'].mean()
sns.distplot(data['总价'])
data['总价'].mean()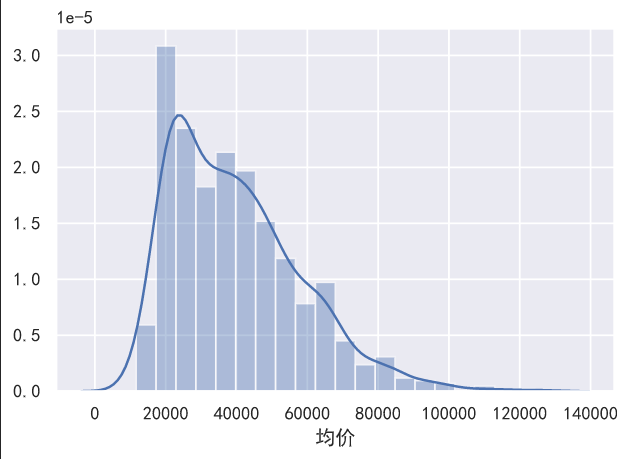
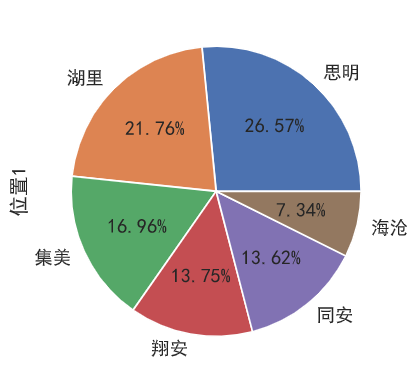
房屋区域分布
有将近一半的二手房都在岛内(思明和湖里)
1 | data['位置1'].value_counts().plot.pie(autopct='%.2f%%') |
 房屋朝向分布
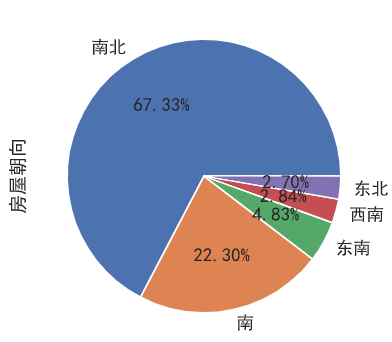
房屋朝向分布
选取前五种最受欢迎的房屋朝向,可以看出,有2/3的房子都是南北朝向:
1 | data['房屋朝向'].value_counts().head(5).plot.pie(autopct='%.2f%%') |
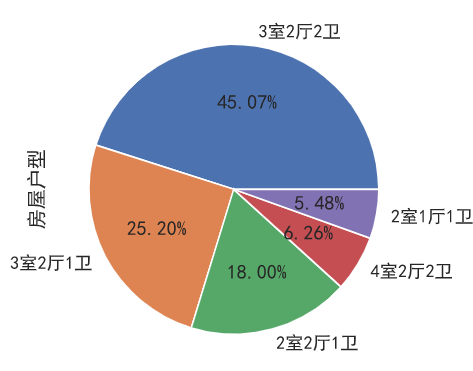
房屋户型分布
同样选取前五种最受欢迎的房屋朝向,可以发现3室2厅2卫的户型最受欢迎:
1 | data['房屋户型'].value_counts().head(5).plot.pie(autopct='%.2f%%') |
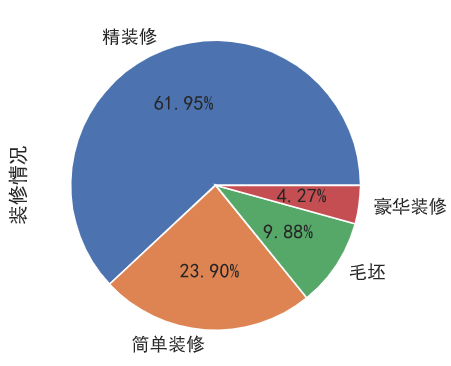
装修情况分布
二手房基本上都是装修好了的,只有不到10%的是毛坯(为啥二手房还有毛坯的?)
1 | data['装修情况'].value_counts().plot.pie(autopct='%.2f%%') |
多变量间关系及可视化
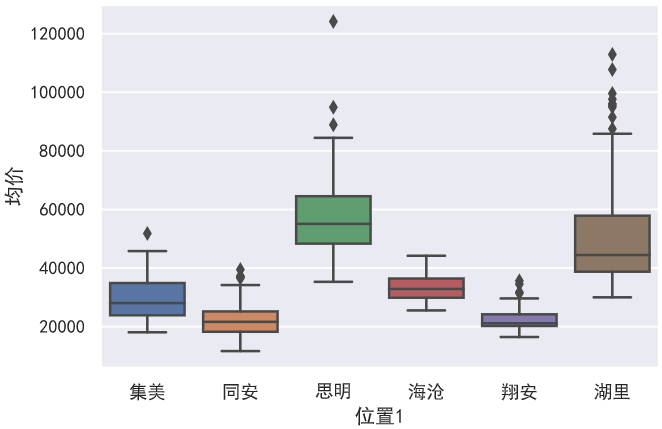
地域与房价
画出各个区域的每平方米价格的箱型图,果然,岛内的房价更可怕了,思明区接近6万/平米,更有12万/平米的天价房,湖里区也接近5万/平米,就算在同安和翔安这两个鸟不拉屎的地方一平米也要两万多了
1 | sns.boxplot(data=data, x='位置1', y='均价') |
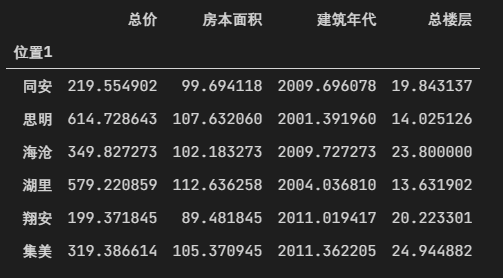
 地域与其他变量 将数据做一个聚合,取平均,可以发现,岛内的房子都比较老,大概都在2000年上下(因为没地方可建了吧),而岛外基本上都在2010年左右,而且岛内的房子就只有十三四层,而岛外的房子有二十层左右,面积也相对来说比岛内的小一点
地域与其他变量 将数据做一个聚合,取平均,可以发现,岛内的房子都比较老,大概都在2000年上下(因为没地方可建了吧),而岛外基本上都在2010年左右,而且岛内的房子就只有十三四层,而岛外的房子有二十层左右,面积也相对来说比岛内的小一点
1 | data.groupby(by=['位置1'])['总价','房本面积','建筑年代','总楼层'].mean() |
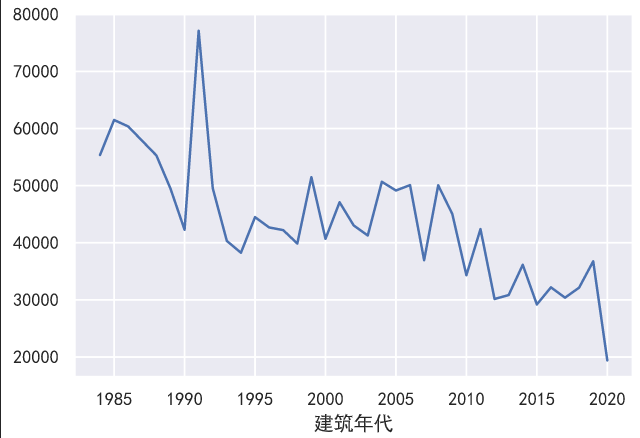
建筑年代与房价
看上去好像越老的房子越贵,上世纪末建的房子最值钱,而最近几年建的房子都不怎么值钱,当然这也跟我们之前分析的区域有关,因为最近建的房子基本都在岛外,所以当然不怎么值钱
1 | data.groupby(by='建筑年代')['均价'].mean().plot() |
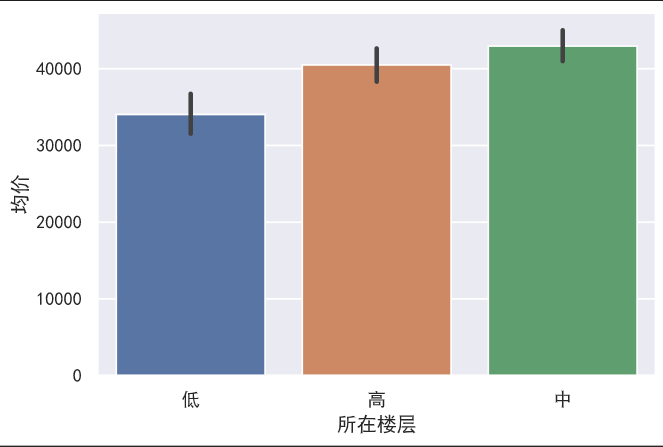
所在楼层与房价
一般来说,大家都不太喜欢低楼层的房子,因为太吵了,当然太高也不行,这种关系,也反映在房价中:
1 | sns.barplot(x='所在楼层', y='均价', data=data) |
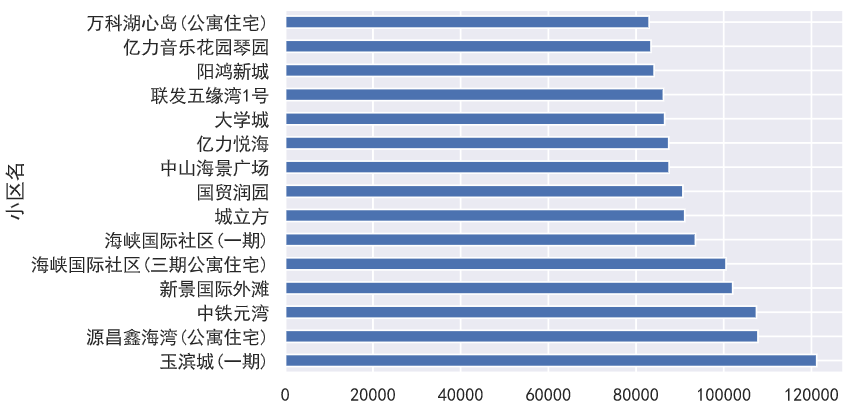
再来看看厦门哪个小区的房子最贵吧,这里选取小区均价最高的15个小区:
1 | data.groupby(by='小区名')['小区均价'].mean().sort_values(ascending=False).head(15).plot(kind='barh') |
地理可视化
前阵子刚好接触到百度地图的API,非常强大,就顺手做个地图可视化吧! 首先需要去百度地图开发者官网( http://lbsyun.baidu.com/)注册一个密钥,然后创建两个应用,一个是服务端的,用来使用Python获取小区坐标,一个是浏览器端的,用来通过修改html源代码创建热力图,具体实现可以参考这篇文章:Python使用百度地图API实现地点信息转换及房价指数热力地图 最后生成的效果如下图所示,可以看出,厦门市最贵的地段基本上就在火车站周围那一块: 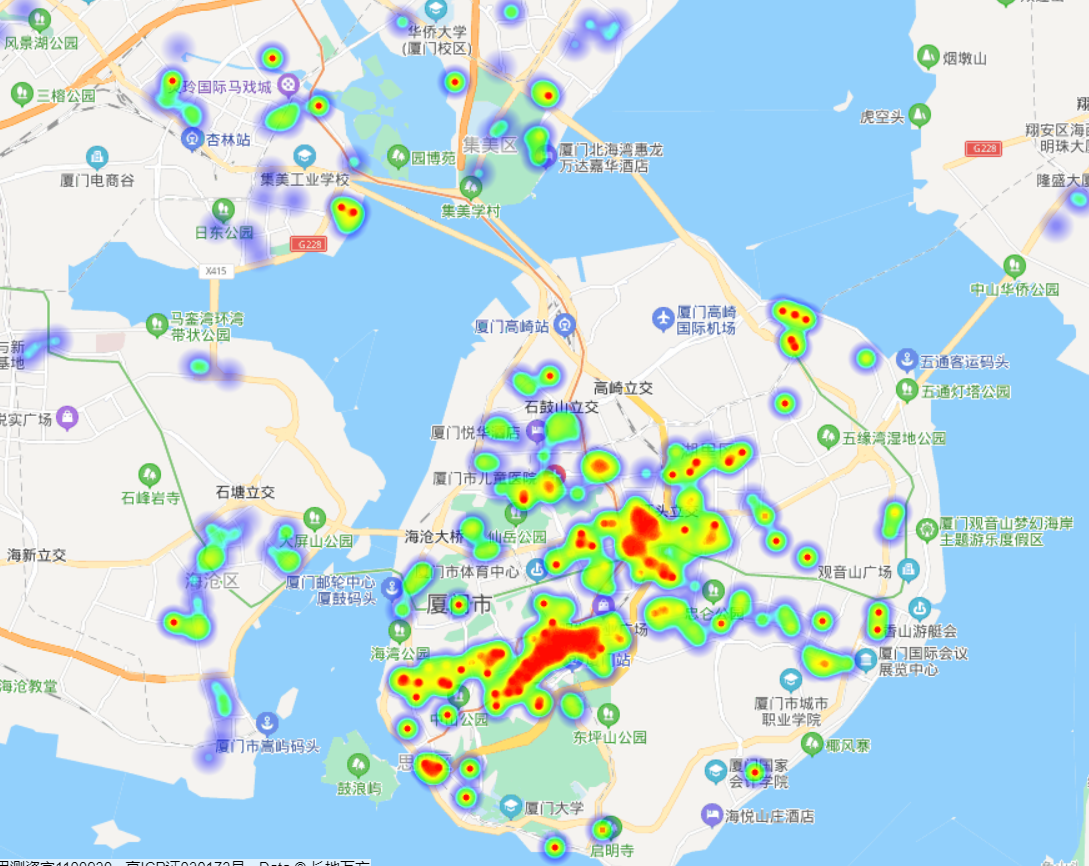 ps: 这里可视化原本想使用 folium,但是存在 folium包存在两个问题,一个是热力图存在 bug,没有渐变效果,另外一个是因为我坐标采用的是百度的坐标,百度的坐标是经过加密的,用在 folium上会存在坐标偏移的情况,故弃用
ps: 这里可视化原本想使用 folium,但是存在 folium包存在两个问题,一个是热力图存在 bug,没有渐变效果,另外一个是因为我坐标采用的是百度的坐标,百度的坐标是经过加密的,用在 folium上会存在坐标偏移的情况,故弃用
预测模型
以每平方米价格为因变量,其余变量为自变量,并将分类变量使用 LabelEncoder 编码,将测试集与训练集以2:8的比例分割: 1
2
3
4
5
6x=data.drop(columns=['小区均价','总价','均价','房屋户型','小区名'])
y=data['均价']
for col in ['位置1','房屋朝向','一手房源','所在楼层','装修情况']:
le = LabelEncoder()
x[col]=le.fit_transform(x[col])
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
决策树
1 | dt = DecisionTreeRegressor() |
随机森林
1 | rf = RandomForestRegressor(n_estimators=2000, n_jobs=-1) |
Catboost
1 | cb=CatBoostRegressor() |
结果对比
| 决策树 | 随机森林 | catboost | |
|---|---|---|---|
| 绝对值误差 | 2885.81 | 2286.76 | 2347.04 |
特征重要性
用随机森林输出特征重要性看看: 1
2
3
4fi = pd.DataFrame(
{'x': x.columns, 'feature_importance': rf.feature_importances_})
fi = fi.sort_values(by='feature_importance',ascending=False)
sns.barplot(x='feature_importance', y='x', data=fi)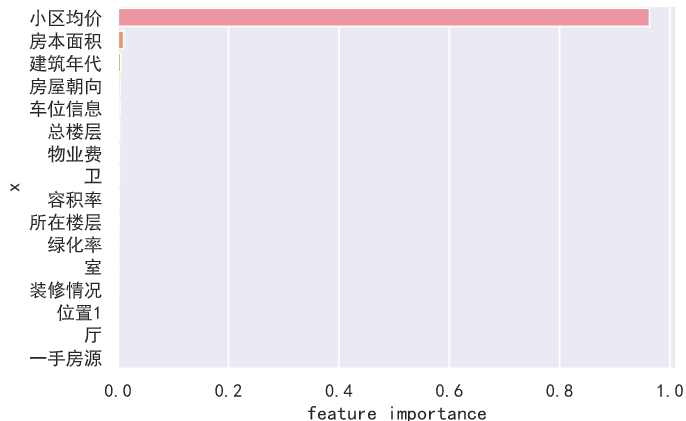 啊这,小区均价一枝独秀,解释力度太大了,把其他特征的信息都全部吃下去了,为了更好的解释其他特征与每平方米价格的关系,我们考虑把它排除在外,再输出一次特征重要性:
啊这,小区均价一枝独秀,解释力度太大了,把其他特征的信息都全部吃下去了,为了更好的解释其他特征与每平方米价格的关系,我们考虑把它排除在外,再输出一次特征重要性: 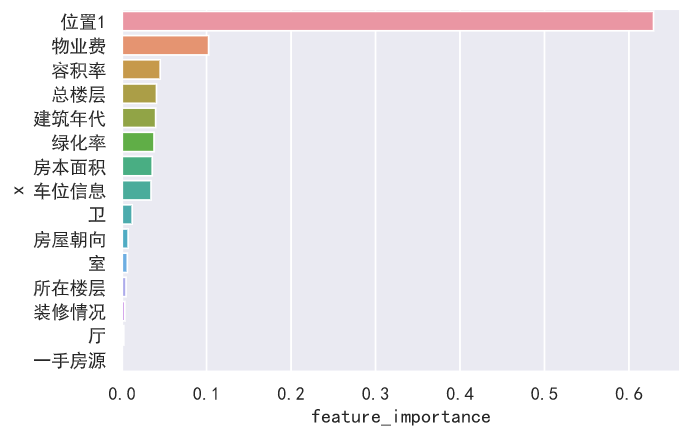 这次就好点了,预测的绝对值误差虽然变成了四千,预测效果变差了,但是解释力度提高了,对房价影响最大的前五个特征为:位置1(区域)、物业费(反映小区的质量)、容积率(反映小区的居住的舒适度)、总楼层、建筑年代,而房屋朝向、所在楼层和装修情况这些特征居然没有想象中的那么重要,看来在厦门,决定一套房子价格的是房子所在小区的属性,而不是你这套房子本身的属性。
这次就好点了,预测的绝对值误差虽然变成了四千,预测效果变差了,但是解释力度提高了,对房价影响最大的前五个特征为:位置1(区域)、物业费(反映小区的质量)、容积率(反映小区的居住的舒适度)、总楼层、建筑年代,而房屋朝向、所在楼层和装修情况这些特征居然没有想象中的那么重要,看来在厦门,决定一套房子价格的是房子所在小区的属性,而不是你这套房子本身的属性。
小结
好了,又一篇文章水完了,这篇文章还是花了我不少时间的,尤其是在研究怎么画图上,看来可视化这方面还是得继续学习一下啊!这个月总体来说还是比较忙的,希望能够坚持每周写一篇吧,下周可能会开始写一些算法的学习笔记。