在时间序列预测中,预测的horizon往往是一段时间,比如下一周的股票价格、销量、天气等等,但是,在将时间序列数据转化为有监督学习时,往往会构造很多特征,其中一个很重要的就是滞后值特征和滑动窗口统计特征,一旦加入这些特征,就会导致有监督学习的多步预测出现问题,比如,我需要构造了一个滞后一天的特征lag1,需要预测接下来两天的值,那么,第一天的是很好预测的,因为我有昨天的值,但是第二天的预测就有问题了,因为昨天的观测值是不知道的啊,在上一篇文章中,我提到了一个递归预测法,但这两天看了一下,其实解决这个问题的方法还不少,所以写篇文章总结下吧。
直接预测法
直接预测法(Direct Multi-step Forecast Strategy),这种方法的思路呢就是,如果不能使用lag特征,那我干脆就不用了。这种方法的可操作空间还是挺大的,可以分为只使用1个模型,使用n个模型(n为需要预测的天数),使用1-n个模型。接下来详细说明下每一种方法。
只使用一个模型
举个例子,现有7月10号-7月15号的数据,需要预测未来3天的销量,那么,我就不能用lag1和lag2作为特征,但是可以用lag3呀,所以就用lag3作为特征构建一个模型:
这种是只使用一个模型来预测的,但是呢,缺点是特征居然要构造到lag3,lag1和lag2的信息完全没用到,所以就有人提出了一种思路,就是对于每一天都构建一个模型。
使用n个模型
这个的思路呢,就是想能够尽可能多的用到lag的信息,所以,对于每一天都构建一个模型,比如对于15号,构建模型1,使用了lag1,lag2和lag3作为特征来训练,然后对于16号,因为不能用到lag1的信息了,但是lag2和lag3还是能用到的,所以就用lag2和lag3作为特征,再训练一个模型2,17号的话,就只有lag3能用了,所以就直接用lag3作为特征来训练一个模型3,然后模型123分别就可以输出每一天的预测值了。
这种方法的优势是最大可能的用到了lag的信息,但是缺陷也非常明显,就是因为对于每一天都需要构建一个模型的话,那预测的天数一长,数据一多,那计算量是没法想象的,所以也有人提出了一个这种的方案,就不是对每一天构建一个模型了,而是每几天构建一个模型。
使用1-n个模型
还是上面那个例子,这次把数据改变一下,预测四天吧,有10号-15号的数据,构建了lag1-5的特征,需要预测16号-19号的数据,那么我们知道16号和17号是都可以用到lag2和lag3的特征的,那么为这两天构建一个模型1,而18号和19号是可以用到lag4和lag5的特征的,那么为这两天构建一个模型2,所以最后就是模型1输出16号和17号的预测值,模型2输出18号和19号的值。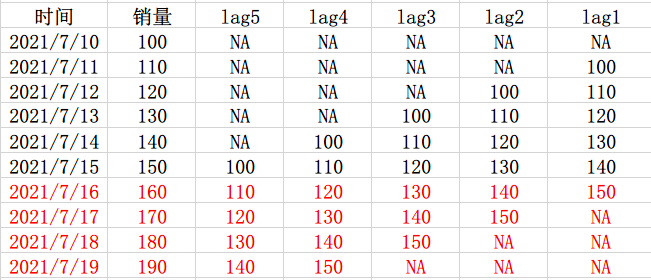
可以发现,这样的话,我们虽然没有尽最大可能的去使用lag特征,但是,计算量相比于使用n个模型直接小了一半。这是kaggle M5比赛第四名的思路。
递归预测法
然后是递归预测法(Recursive Multi-step Forecast),不知道预测值对应的滞后值怎么办?就用之前的预测值当真实值呗!举个例子,有10号-15号的数据,构建了lag1特征,需要预测未来3天的销量,那么15号的lag1特征可以直接用14号的值,假设预测出来结果是150,那么,在16号,lag1的真实值也就是15号的值虽然不知道,但是可以直接用15号的预测值填充呀,依次类推,17号的lag1也可以直接用16号的预测值填充,这就是递归预测法。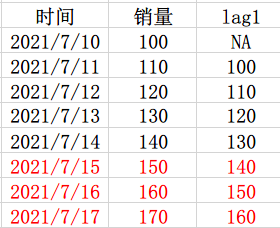
但是,这种方法有一个缺陷就是会造成误差累计,还是上面那个例子,假设我15号那天预测错了,那么16号那天的输入就也是错的,那用来预测就更错了啊,所以,使用这种方法的话,一旦预测出错就会越错越离谱,这种方法会有着较高的偏差。
直接-递归混合预测法
直接预测法使用到的lag信息少,并且需要建的模型多,方差较大,递归预测法只使用了一个模型,并且lag的信息也全用上了,但是容易造成误差累计,偏差较大。所以,有人把上面两种方法直接结合了起来,试图平衡方差和偏差,这里就叫直接-递归混合预测法吧,混合的方式还挺多的,我看到的就三种了。
混合一
同时使用直接法和递归法,分别得出一个预测值,然后做个简单平均,这个思路也就是采用了模型融合的平均法的思想,一个高方差,一个高偏差,那么我把两个合起来取个平均方差和偏差不就小了吗,这个方法是kaggle M5比赛top1用的解决方案。
混合二
这种方法是这篇论文提出的:《Recursive and direct multi-step forecasting: the best of both worlds》,有兴趣可以自己去读下,大概说的就是先使用递归法进行预测,然后再用直接法去训练递归法的残差,有点像boosting的思想,论文花了挺大篇幅说了这种方法的无偏性,不过,这种方法也就是存在论文中,暂时没见到人使用,具体效果还不知道。
混合三
简单来说就是使用到了所有的lag信息,同时也建立了很多模型,还是这个例子,首先用10号-14号的数据训练模型1,得到15号的预测值,然后将15号的预测值作为16号的特征,同时用10号-15号的数据训练模型2,得到16号的预测值,最后使用16号的预测值作为17号的特征,使用10号-16号的数据训练模型3,得到17号的预测值。
这种方法说实话我不能很get到他的好处在哪,相比于递归预测法,不就是训练时多了几条数据吗?还是会有误差累计的问题吧,或许是我没有理解明白吧,kaggle favorita-grocery第一名的方案好像也使用的这个
多输出法
在传统的机器学习中,是无法实现多输出的,只能输出一个值,但是在深度学习的模型中,就可以通过调节输出神经元的个数,从而实现多输出的功能,还有一些是使用seq2seq结构的,深度这块的时间序列预测目前了解的比较少,这里不再展开了。
总结
目前针对时间序列预测的多步输出问题大概就这几种方法,其中针对机器学习的直接法、递归法还有直接-递归混合法,这几种方法在kaggle上都有应用,也没有说哪种方法就一定好,这个需要就具体问题具体分析,多尝试一下才能知道在某种问题上哪种方法表现更好。