对于结构化数据建模,现在主流使用的模型是都是树模型,lightgbm、xgboost等,这些模型有一个很重要的特性就是可以输出特征重要性,可以用来指导特征工程,但是却不能直接用来做特征选择,这篇文章就先主要谈谈使用特征重要性来筛选特征的缺陷,然后介绍一种基于特征重要性改进的特征选择方法——Boruta。
使用特征重要性来筛选特征的缺陷
- 特征重要性只能说明哪些特征在训练时起到作用了,并不能说明特征和目标变量之间一定存在依赖关系。举例来说,随机生成一大堆没用的特征,然后用这些特征来训练模型,一样可以得到特征重要性,但是这个特征重要性并不会全是0,这是完全没有意义的。
- 特征重要性容易高估数值特征和基数高的类别特征的重要性。这个道理很简单,特征重要度是根据决策树分裂前后节点的不纯度的减少量(基尼系数或者MSE)来算的,那么对于数值特征或者基础高的类别特征,不纯度较少相对来说会比较多。
- 特征重要度在选择特征时需要决定阈值,要保留多少特征、删去多少特征,这些需要人为决定,并且删掉这些特征后模型的效果也不一定会提升。
正由于特征重要性存在的这些缺陷,所以一般来说,特征重要性只能用来指导特征工程,比如看排名前几的特征都有啥,之后可以怎么根据这几个特征进行交叉,但是是不能够用来作为特征选择的依据的。但是特征重要性也不是完全没有用,使用得当还是能够作为特征选择的手段的,比如Boruta和Null Importance的特征选择就是基于特征重要性来做的。
Boruta
Boruta的名字来自斯拉夫神话中一个住在树上里的恶魔,专门吃贵族,大致含义就是,专门用来剔除树模型那些特征重要性看起来很大,但是实际上并没有用的特征。
Boruta的主要思想包含两个,阴影特征(shadow feature)和二项分布,下面一一阐述:
阴影特征
特征重要性的一个缺陷就是无论这些特征的效果如何,重要性都是在这些特征之间对比,就有可能出现矮个里面选高个的现象,那能不能让他们和随机生成的特征比呢,按理来说随机生成特征的重要性应该都很低,那么这样就有了一个基准,就可以识别出哪些特征是有用的了。
阴影特征的思想就是把原来所有特征的取值都打乱,打乱后的特征就叫做阴影特征(这里用打乱原来特征的取值而不是新生成特征一个好处就是就保留了原来特征的分布,而不用生成一个新的分布),然后把这些阴影特征加入到原来的数据集中进行训练,如果原始特征的特征重要性还不如阴影特征的话,那说明这个原始特征的效果还不如随机的,可以直接剔除,具体来说步骤如下:
- 对于一个包含有m个特征的数据集,对于每个特征都会创建一份副本
- 将特征副本的取值打乱顺序,得到m个阴影特征
- 将m个阴影特征加入到原数据集中进行训练,输出特征重要性
- 观察m个阴影特征的特征重要性的最大值,将之与原始特征的重要性进行比较,如果原始特征的重要性还不如阴影特征的话,那么就说明这个原始特征是没有用的
不过这样做还是有个问题,因为这样只做了一次实验,会不会有随机性在里面呢?碰巧某个阴影特征就是特别的强,因此需要做多次实验,才能保证结果更可靠,这就是Boruta的第二个思想,用迭代的方式来进行特征选择。
二项分布
前面说到,需要做多次试验才能保证结果更可靠,那么做完多次试验后怎么判断某个特征的去留?假设做了20次实验,然后有三个变量,age、height和weight,在20次实验中,age都被保留了,height被保留了4次,而weight一次都没被保留,那么应该选择哪些变量保留?哪些变量剔除呢?
这里就用到了二项分布,假设每个特征被保留和被剔除的概率都是0.5的话,就跟抛硬币一样,所以n次实验的概率遵从二项分布,就可以通过设置一个阈值(如\(p=0.01\)),把分布的两端截断,分为三个区域:
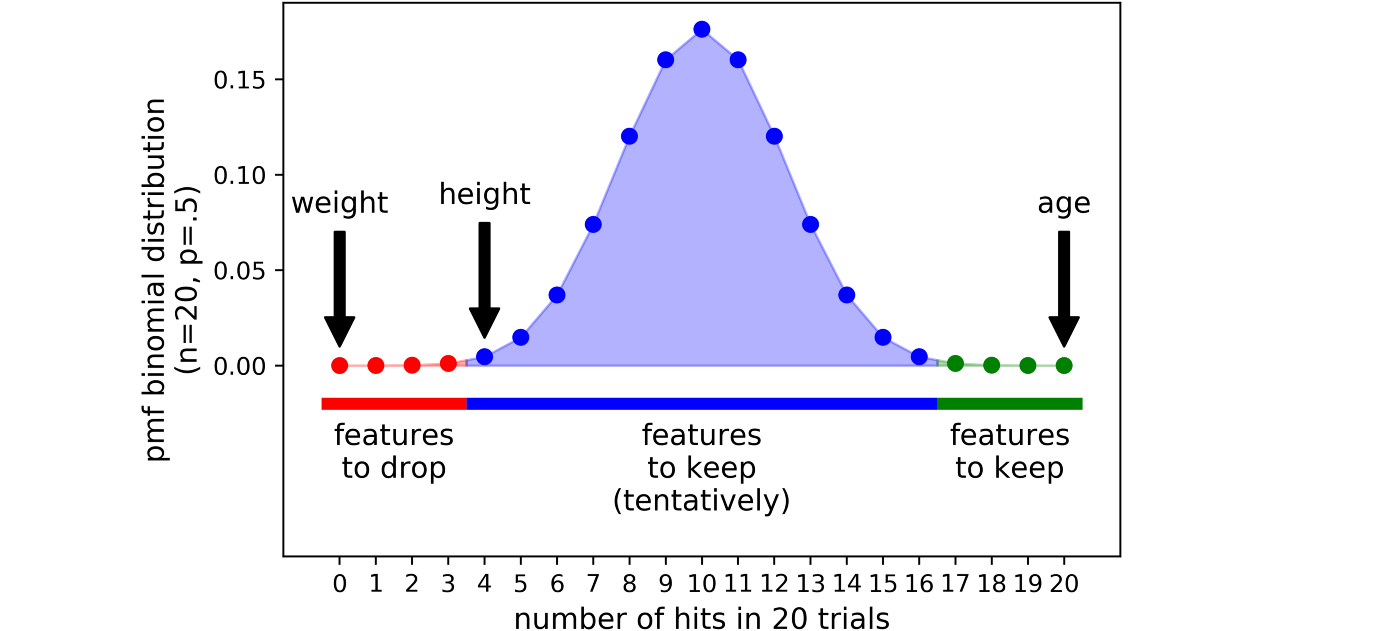
- 拒绝区域(红色):落在这块区域的特征在大部分实验中都被剔除了,因此是无用特征,可以直接剔除
- 不确定区域(紫色):落在这块区域的特征,有时候被剔除了,有时候又被保留,这时候就需要自行决定是否保留,算法默认保留
- 接受区域(绿色):落在这块区域的特征,大部分实验中都被保留了,可以视为有用特征。
使用
Boruta原本是R的包,现在也有了Python实现,可以直接调包使用: 1
pip install boruta
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from boruta import BorutaPy
# load X and y
# NOTE BorutaPy accepts numpy arrays only, hence the .values attribute
X = pd.read_csv('examples/test_X.csv', index_col=0).values
y = pd.read_csv('examples/test_y.csv', header=None, index_col=0).values
y = y.ravel()
# define random forest classifier, with utilising all cores and
# sampling in proportion to y labels
rf = RandomForestClassifier(n_jobs=-1, class_weight='balanced', max_depth=5)
# define Boruta feature selection method
feat_selector = BorutaPy(rf, n_estimators='auto', verbose=2, random_state=1)
# find all relevant features - 5 features should be selected
feat_selector.fit(X, y)
# check selected features - first 5 features are selected
feat_selector.support_
# check ranking of features
feat_selector.ranking_
# call transform() on X to filter it down to selected features
X_filtered = feat_selector.transform(X)
总结
总结来说,Boruta就是生成了随机的阴影特征加入到原数据中,并比较阴影特征和原始特征的重要性大小,然后多次迭代,最终根据二项分布来比较特征优于阴影特征的次数来决定是否保留或者剔除特征,这样筛选最后得到的特征都是对于模型的预测能够起到积极作用的特征,注意到这是能够起到积极作用,但是并不代表特征筛选后一定会使得预测的效果最好,不过根据自己的实验,使用Boruta之后的效果基本上都不亚于原来未筛选时的效果,并且训练速度也大大加快了。