做机器学习时往往会通过特征交叉来衍生出一系列的特征,那么如何来确保这些特征是有用的呢?太多的特征一方面会加重模型的负担,跑得很慢,另一方面无效的特征也会使得模型效果下降,因此就需要一些特征选择的方法来剔除无效的特征,这篇文章就主要总结下特征选择的几种基本思路。
 过滤法
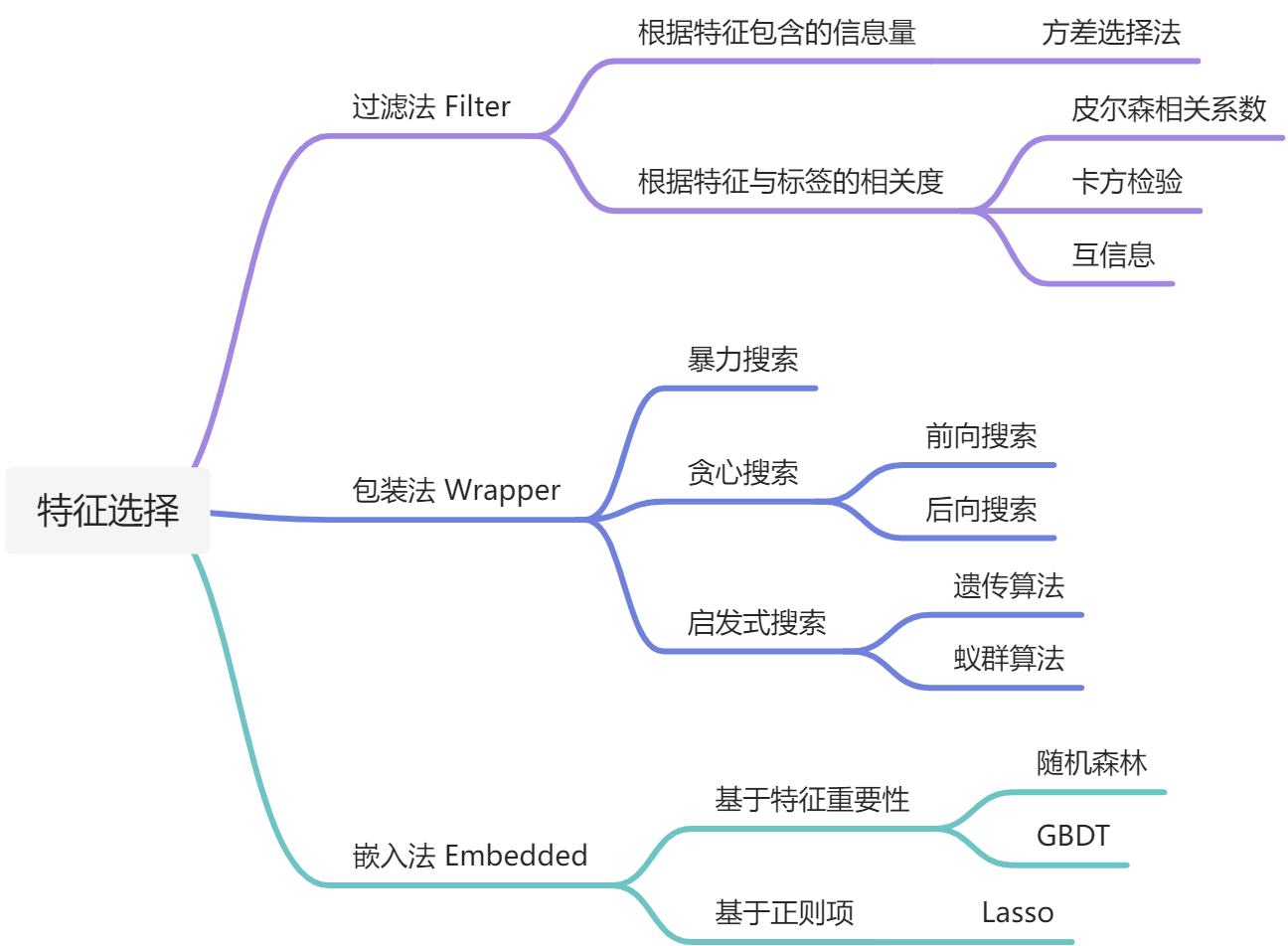
过滤法
过滤法的思想就是不依赖模型,仅从特征的角度来做特征的筛选,具体又可以分为两种方法,一种是根据特征里面包含的信息量,如方差选择法,如果一列特征的方差很小,每个样本的取值都一样的话,说明这个特征的作用不大,可以直接剔除。另一种是对每一个特征,都计算关于目标特征的相关度,然后根据这个相关度来筛选特征,只保留高于某个阈值的特征,这里根据相关度的计算方式不同就可以衍生出一下很多种方法:
- Pearson相关系数
- 卡方验证
- 互信息和最大信息系数
过滤法的优势在于效率非常快,不用跑模型就能很快筛选出一批的特征,不过缺陷是筛选出来的特征对于模型不一定是有用的,并且可能会有冗余特征,而且也不能考虑到特征之间的相互作用。
包装法
与过滤法不同,包装法是根据训练模型的效果来筛选特征的,所以第一步就是先划分训练集和测试集,然后搜索一个最优的特征子集,使得模型在测试集上的指标表现最好。根据搜索方式的不同又可以分为以下三种类型:
- 暴力搜索:穷举所有的特征子集,获取最好的一个,不过计算复杂度是指数级的,一般不会用
- 贪心搜索:分为前向搜索和后向搜索,就是每次增加一个或者减少一个特征,看模型的效果会不会变好,依此来选择特征是否保留,计量里面学的逐步回归就属于这种方法
- 启发式搜索:根据遗传算法、模拟退火、蚁群算法等启发式算法来搜索最优的特征子集
包装法的优势在于选出的特征都是对于模型的效果有提升的,但是缺陷是需要训练很多次模型来评估特征的作用,效率低下,只能在特征和样本量相对较少的时候用一下。
嵌入法
嵌入法的嵌入就是把特征的选择嵌入到模型的训练过程中,在模型训练完成之后便可得出哪些特征是有用的,哪些特征是没用的。这种方法就需要特定的模型才能做了,具体来说有两种:
- Lasso:通过控制惩罚项\(\lambda\)的大小,可以将一些变量的系数压缩为0,就起到了特征选择的作用
- 树模型:随机森林和GBDT这些树模型,可以输出特征重要性,通过特征重要性可以大概知道哪些特征有用,哪些没用
嵌入法的同时兼顾了包装法和嵌入法的优点,不过实际使用过程中,还是会有些问题,尤其是用特征重要性,之后更新下两篇文章,主要谈谈使用特征重要性作为特征选择的缺陷,以及两种基于特征重要性改进的特征选择方法:Boruta和Null Importance。
参考
- 【机器学习】特征选择(Feature Selection)方法汇总 - 知乎
- 《美团机器学习实践》