最近在做nlp相关的任务,发现无脑上bert就能达到很好的效果了,于是就去看了原论文,写篇文章好好总结一下吧!
背景
在计算机视觉领域,预训练已经被证明是行之有效的了,比如ImageNet,训练了一个很大的模型,用来分类1000种东西,然后底层的模型架构就能很好的捕捉到图像的信息了,就可以直接迁移到其他任务上,比如一个猫狗的二分类问题,就只需要把模型拿来微调,接一个softmax输出层,然后重新训练几个epoch就能达到很好的效果了。类似的预训练一个大模型然后拿来做迁移学习的思想也被用在了nlp上,语言模型的预训练用在下游任务的策略主要有两种:
- 基于特征(feature-base):也就是词向量,预训练模型训练好后输出的词向量直接应用在下游模型中。如ELMo,用了一个双向的LSTM,一个负责用前几个词预测下一个词,另一个相反,用后面几个词来预测前一个词,一个从左看到右,一个从右看到左,能够很好地捕捉到上下文的信息,不过只能输出一个词向量,需要针对不同的下游任务构建新的模型。
- 基于微调(fine-tuning):先以自监督的形式预训练好一个很大的模型,然后根据下游任务的不同接一个输出层就行了,不需要再重新去设计模型架构,如OpenAI-GPT,但是GPT用的是一个单向的transformer,训练时用前面几个词来预测后面一个词,只能从左往右看,不能够很好的捕捉到上下文的信息。
ELMo虽然用了两个单向的LSTM来构成一个双向的架构,能够捕捉到上下文信息,但是只能输出词向量,下游任务的模型还是要自己重新构建,而GPT虽然是基于微调,直接接个输出层就能用了,但是是单向的模型,只能基于上文预测下文,没有办法很好的捕捉到整个句子的信息。
因此,BERT(Bidirectional Encoder Representations from Transformers)就把这两个模型的思想融合了起来,首先,他用的是基于微调的策略,在下游有监督任务里面只需要换个输出层就行,其次,他在训练的时候用了一个transformer的encoder来基于双向的上下文来表示词元,下图展示了ELMo、GPT和BERT的区别:
BERT很好的融合了ELMo和GPT的优点,论文中提到在11种自然语言处理任务中(文本分类、自然语言推断、问答、文本标记)都取得了SOTA的成绩。
核心思想
BERT的模型结构采用的是transformer的编码器,模型结构如下,其实就是输入一个\(n\times h\)(n为最大句子长度,h为隐藏层的个数)的向量,经过内部的一些操作,也输出一个\(n\times h\)的向量。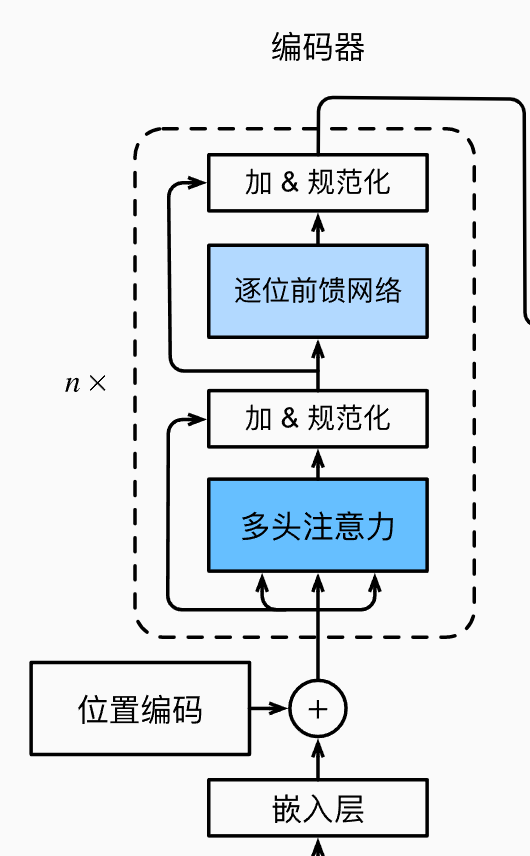
根据模型的一些参数设置的不同,BERT又分为:
- \(BERT_{BASE}\):transformer层12,隐藏层大小768,多头注意力个数12,总共1.1亿参数
- \(BERT_{LARGE}\):transformer层24,隐藏层大小1024,多头注意力个数16,总共3.4亿参数
BERT主要的工作在于对于输入表示的改造以及训练目标的设计。
输入表示
在自然语言处理中,有的任务的输入可能只需要一个句子,比如情感分析,但是有的任务的输入是需要一对句子的,比如自然语言推断,因此,为了使Bert能够用在更多的下游任务上,BERT的输入被设计为不仅可以输入一个句子,也可以输入一个句子对。
不管输入的是一个句子还是句子对,BERT的输入的第一个词元都是一个特殊的词元
- 对于一个句子,BERT的输入结构为:
句子 - 对于一个句子对,BERT的输入为:
句子1 句子2
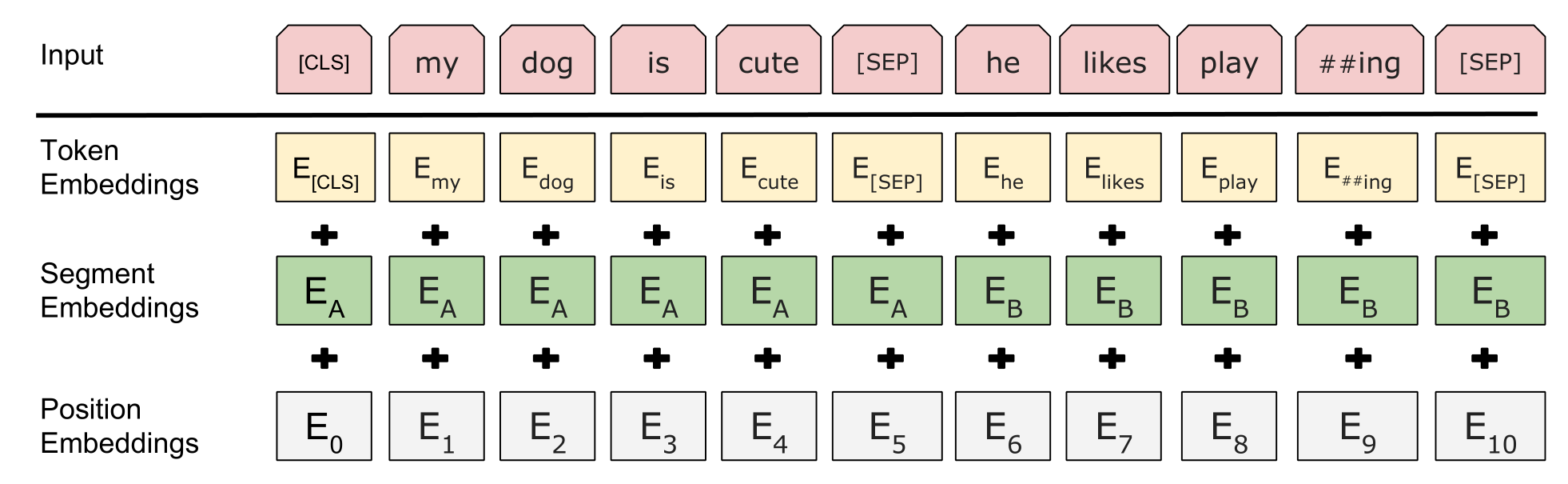
由于注意力机制是无法捕捉到位置信息的,因此BERT还加了一个position embedding,这里的position embedding的参数是自己学出来的,用来加在每个词元上的token embedding。
并且,为了区分句子对,BERT又训练了一个两个Segment Embeddings,分别加在原来的两个句子对应的token embedding上。
因此,最后BERT的输入就是三个embedding相加的结果,如下图所示:
Masked Language Model (MLM)
前面说到,之前的预训练模型都是单向的,也就是用前几个词来预测下一个词,这样有个缺陷就是无法捕捉整个句子的上下文信息。因此BERT采用了在输入时随机mask词元的方式,然后基于上下文,在输出层里面预测这些被mask的词元,其实这就是完型填空了,就像我们以前高中英语做的一样,要能够填空,那么就得对上下文的语义有一个比较深入的了解,因此bert最后训练出来的参数就能够很有效的表征整个句子的语义。
具体来说,输入的时候会会把一个句子中的词随机mask掉一部分,比如:“你笑起来真好看”变成“你
但是该遮掉多少词也是个问题,论文里给了一个15%的比例,在训练时将15%的词替换为用一个特殊的“
- 80%时间为特殊的“
“词元(例如,“this movie is great”变为“this movie is ”; - 10%时间为随机词元(例如,“this movie is great”变为“this movie is drink”),这里的目的是为了引入一些噪声,有点像纠错了;
- 10%时间内为不变的标签词元(例如,“this movie is great”变为“this movie is great”)
Next Sentence Prediction (NSP)
因为研究者想让bert还能够适应像自然语言推理这类的任务,因此还加入了另一个任务,也就是当输入的是一个句子对的时候,BERT会预测这两个句子在上下文中是否是相邻的,具体在训练时,就会有50%概率输入的句子对是相邻的,50概率输入的句子对是不相邻的,其实就是一个二分类任务,这里刚好用之前提到的句子开头那个
最终把MLM的损失函数和NSP的损失函数加起来就是BERT最终的损失了,可以用Adam来做优化。
BERT的使用
接下来主要讲讲BERT在各个任务上是怎么使用的,其实也就是接一个输出层啦。
- 文本分类任务:和NSP类似,在
这个词元的输入顶部接一个softmax分类层 - 问答任务:输入一个文本序列,需要从这个序列中找到答案的位置,就是接两个输出层,一个用来代表答案开始的地方,一个用来代表答案结束的地方。
- 命名实体识别(NER)任务:输入一个文本,标记文本中每个词元属于什么类型,直接把每个词元的输出向量输入到一个分类层就行。
具体在使用的时候,直接使用huggingface的🤗 Transformers就行,里面内置了很多预训练模型,并且对于每个任务也都有很好的封装,使用成本很低。