1st place solution
文档链接:1st place solution
整体框架: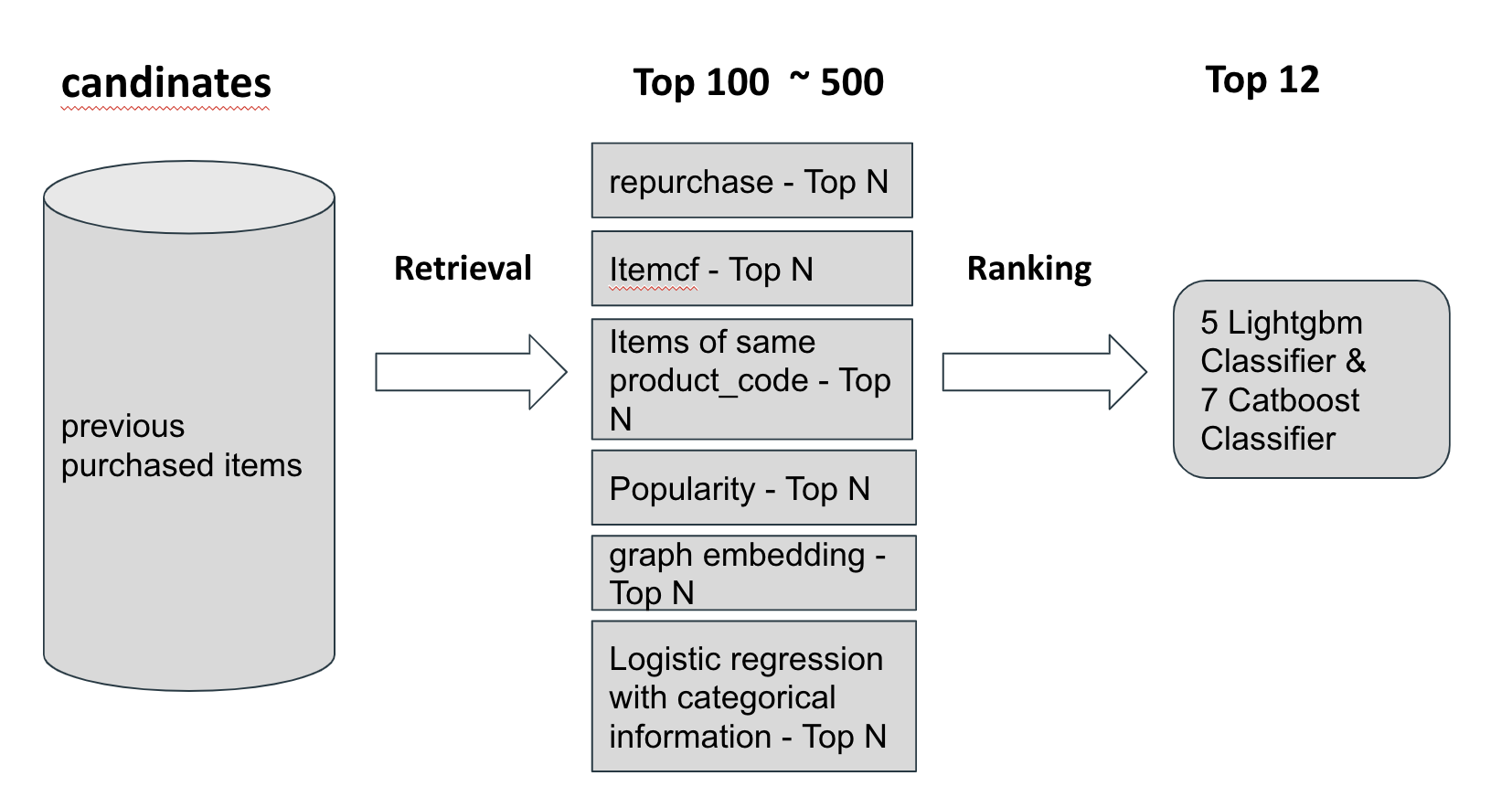
召回策略
- 用户上次购买的商品
- Item CF
- 属于同个product code的商品
- 热门商品
- graph embedding:ProNE
- 逻辑回归:训练Logistic回归模型,从前1000个热门商品中检索到50~200个商品
召回策略一共为每个用户召回了100-500个商品,使用HitNum@100来评估召回策略的质量,尽可能覆盖更多的正样本。
特征工程
| 类型 | 描述 |
|---|---|
| Count | user-item, user-category of last week/month/season/same week of last year/all, time weighted count… |
| Time | first,last days of tranactions… |
| Mean/Max/Min | aggregation of age,price,sales_channel_id… |
| Difference/Ratio | difference between age and mean age of who purchased item, ratio of one user's purchased item count and the item's count |
| Similarity | item2item的协同过滤分数, item2item(word2vec)的余弦相似度, user2item(ProNE)的余弦相似度 |
排序模型
5个lightgbm classifier + 7个catboost classifier
不同的分类器分别用不同的时间跨度以及召回数量的数据进行训练,如下图所示: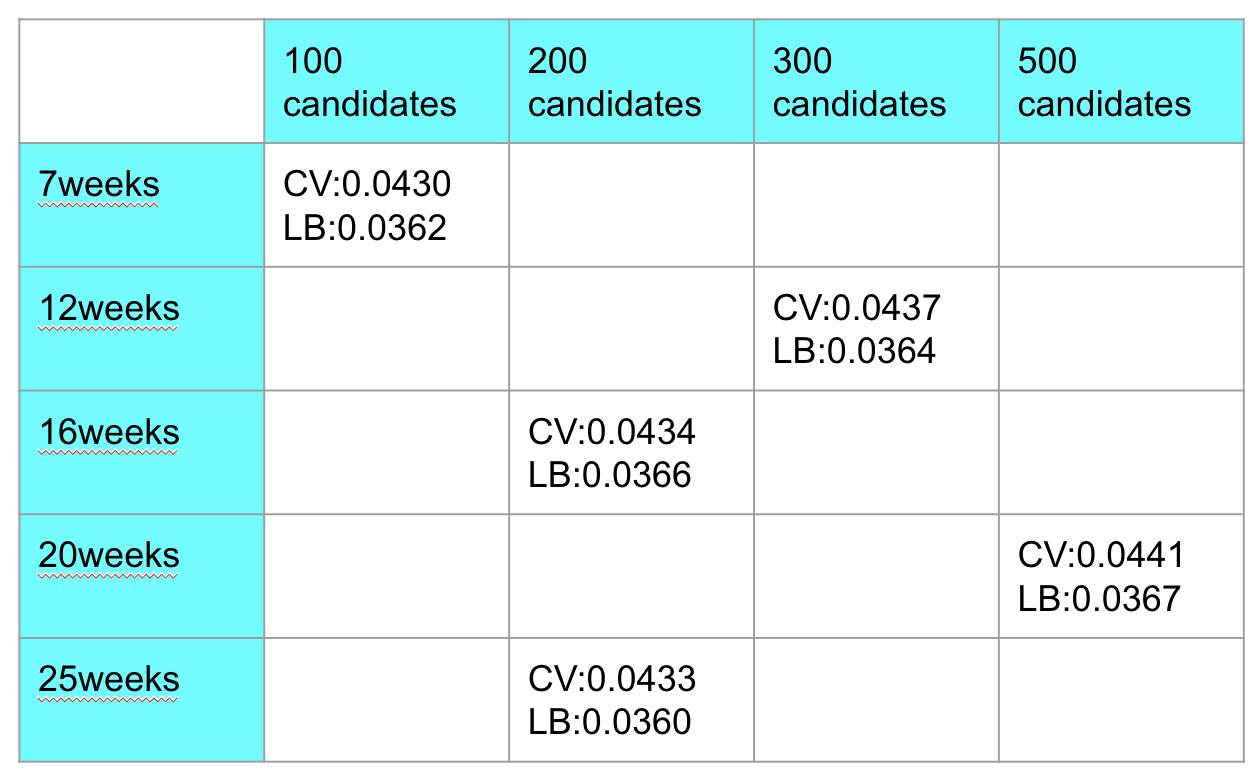
CV策略
优化技巧
- 模型推理优化:使用TreeLite 来优化lightgbm推理的速度(快了2倍),caboost-gpu版本比lightgbm-cpu版本快了30倍
- 内存优化:类别特征用了labelencoder,并且使用了reduce_mem_usage函数
- 特征存储:将创建的特征保存为feather格式,方便使用
- 并行:将用户分为28组,在多个服务器上同时进行推理
- 机器:128g内存,64核CPU, TITAN RTX GPU(真特么有钱啊!)
亮点
2nd place solution
文档链接:2nd place solution
召回策略
热门商品,基于不同的维度进行召回:
- 用户属性:如不同年龄、地域购买的热门商品(其中,基于地域postal_code的召回最为显著的提升了分数)
- 商品属性:如果用户购买了具有特定属性的商品,会寻找具有相同属性的热门商品
- 使用不同的时间窗口:1、3、7、30、90天。
用户历史购买过的全部商品
使用MobileNet embedding计算的图像相似度及进行召回
特征工程
用户基本特征:包括购买数量、价格、sales_channel_id
商品基本特征:根据商品的每个属性进行统计,包括:times, price, age, sales_channel_id, FN, Active, club_member_status, fashion_news_frequency, last purchase time, average purchase interval
用户商品组合特征:基于商品每个属性的统计信息,包括:num, time, sales_channel_id, last purchase time, and average purchase interval
年龄商品组合特征:每个年龄组的商品受欢迎程度。
用户商品回购特征:用户是否会回购商品以及商品是否会被回购
高阶组合特征:例如,预测用户下次购买商品的时间
排序模型
魔改的lightgbm ranker,使用lambdarankmap作为目标函数(从xgboost里面copy的代码),比lightgbm原生的lambdarank目标要好。
cv策略
亮点
使用MobileNet生成了图像的embedding特征
各种高阶特征:用户是否会回购商品以及商品是否会被回购、用户下次购买商品的时间等
3rd place solution
文档链接:3rd place solution
作者说他整体建模的套路都和其他人差不多,因此分享了两点他觉得跟别人不同但是有用的东西:
召回策略特征:这个商品被哪种策略召回,以及被召回时的排名,加上这两个特征,以及将召回的数量从几十增加到上百,将LB分数从0.02855提高到0.03262,直接从银牌区进去了金牌区,此外,如果只增加召回的数量,而不添加增加召回的特征的话,CV分数非常低。
BPR 矩阵分解得到的用户-商品相似度特征:用户和商品的相似性特征对排序模型很重要。关于item2item相似性的特征,例如Buyd together计数和word2vec,在大多数竞争对手的模型中都很常用,这些特征也大大提高了我的分数,但最能改善我的模型的是通过BPR矩阵分解获得的user2item相似性。这个BPR模型是在目标周之前(每周训练一个BPR)使用implicit训练所有交易数据的。BPR相似性的auc约为0.720,而整个排序模型的auc约为0.806,其他单一特征的最佳auc约为0.680。最后,这个相似性特征将我的LB分数从0.03363提高到了0.03510,这将我从金牌区带到了奖品区。
4th place solution
文档链接:4th place solution
整体思路: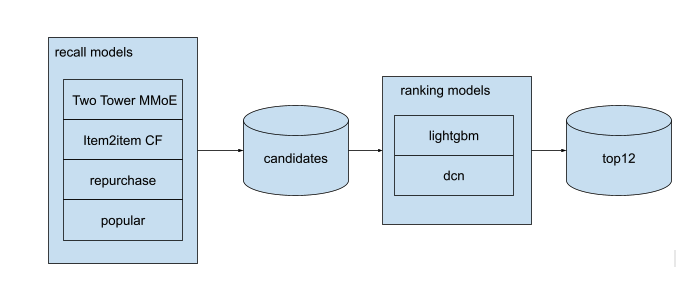
召回策略
- item CF
- 最近购买:用户最近购买的12个商品
- 热门商品:上周的热门商品
- Two Tower MMoE:作者主要关注这个模型的训练,因为它不仅能够为用户生成任意多的候选商品,还能够创建用户-商品相似度特征,这是模型的架构:
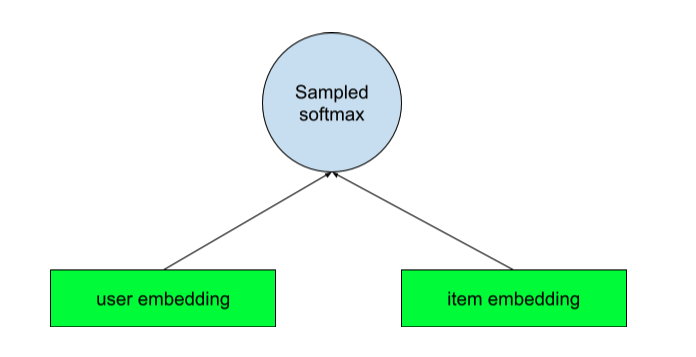
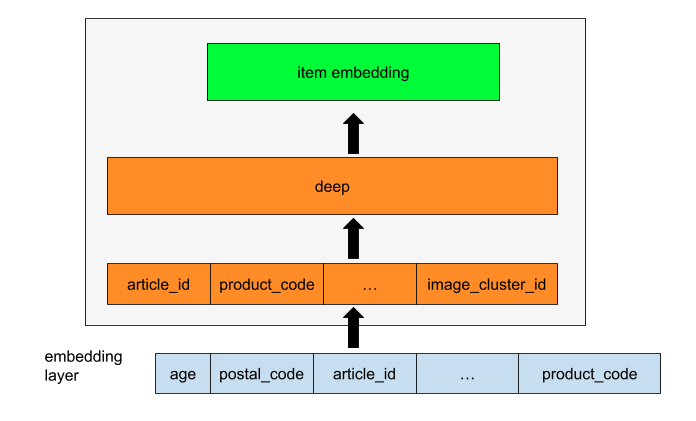
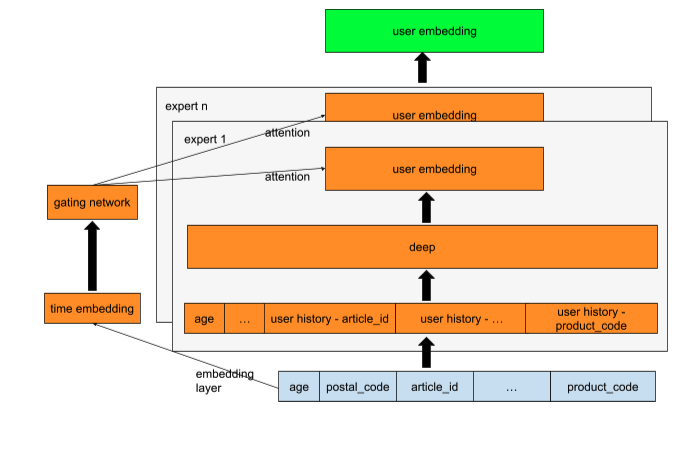
对于用户侧的tower,作者还用了一个门控网络,以确保用户塔可以通过使用不同的expert为最近的活跃客户和非活跃客户进行学习。
冷启动
用户冷启动:双塔MMoE可以使用用户基础特征为没有购买日志的用户生成候选商品。
商品冷启动:除了商品的基本特征,作者还用了图像和文本的特征
亮点
5th place solution
文档链接:5th place solution
召回策略
- 用户上一篮子的购买(以及和用户上次购买商品相同product code的商品),最近购买的商品
- User CF
- Item CF
- word2vec
- 经常会被一起购买的商品
- 根据用户的属性(年龄、性别等)召回的热门商品
关于召回的数量,作者使用一个正样本的比例作为阈值来控制的,比如把阈值设为0.05的话,然后某个策略召回100个商品,正样本比例为0.01,那么可以召回少一点的商品,比如50个,这样刚好可以使得正样本比例刚好卡在0.05.
Embedding方法
商品的图像信息:使用swin transformer来提取embedding
商品的文本信息:使用SentenceTransformer提取
tf-idf获取商品的embedding
特征工程
- 用户特征
- 商品特征
- 用户-商品特征:如相似度特征,聚合的统计特征等
对于第1部分和第2部分,可以进行计算并保存一次,然后与第3部分的特征合并。这种方法可以节省很多时间,尤其是在推理的时候。
模型
作者用了大量时间在召回策略的设计上,因此只用了lightgbm单模
亮点
- 召回策略非常丰富,一共用了21种
- 图像和文本的embedding,图像用了swin transformer,文本用了SentenceTransformer